Hi, I’m Philip Phuc Nguyen, a software engineer and a proud dad.
I started my 13-year career as a full-stack developer and later had other fancy titles such as senior engineer, tech lead, supreme commander, etc., but I mostly consider myself an explorer of ideas.
My favorite kind of work is when there’re unconventional problems and/or constraints that can’t be solved by established good practices and patterns. I enjoy researching, experimenting and leading a team towards a novel solution for those challenges. Over the past 13 years I’ve designed solutions and architectures that transformed entire systems, improved performance by 10x, grew a revenue channel by 5x, reduced annual infrastructure cost by hundreds of thousands of dollars, and most recently put AI-powered pipelines into production. Some of these projects are mentioned below.
On the personal side, I often think of myself as a team facilitator. I had experience in almost all typical positions in tech companies (including being the founder of one) and can be a good collaborator, mentor or leader in different circumstances. I value team and engineering culture, and in fact consider it my #1 priority in evaluating a job opportunity.
Outside of tech I enjoy books, movies (from Hayao Miyazaki and Christopher Nolan), badminton, pickleball, and spending time with my family.
Notable Projects
Most of my work lives in the Node.js and AWS ecosystem. The newest project below comes from my current focus, AI engineering in production, while the earlier ones date back to my Meteor years.
Competitive Intelligence Pipeline
This write-up intentionally stays at the architecture level. Competitor names and business numbers belong to the business, so they stay out of public posts.
Challenge
Reebelo is a marketplace for refurbished electronics operating across North America, Australia, New Zealand and Asia-Pacific. In this market, prices move constantly: the same device can change price many times a day, across many competitor marketplaces and regions at once.
Pricing competitively requires continuous, structured visibility into those movements. The scale makes manual tracking impossible, and the naive automated approach (run an LLM over every scraped page) would be prohibitively expensive.
Solution
I designed the pipeline around one principle: every phase exists to make the next phase cheaper. And it is an evolution rather than a rewrite: the design grew out of the price collection and AI product mapping systems I built for Reebelo, which already run in production, and builds the new layers around that proven core.
Phase 1 - Catalog discovery. Scheduled sweeps enumerate competitor catalogs per region, discovering newly appeared listings and refreshing the tracked set (EventBridge schedules driving ECS workers). Listings that disappear are marked rather than deleted, since a delisting is itself a market signal.
Phase 2 - Collection and change gate. Prices and offers ride structured batch endpoints several times a day, hundreds of listings per call, and the captured prices feed Reebelo’s repricing directly. Listing content takes the second path: fetched through a managed proxy layer, snapshotted to S3 and content-hashed, so unchanged content stops here and costs nothing downstream. One hard-won detail: the hash is taken over structured content, never over rendered pages, which carry per-session noise and never hash-equal.
Phase 3 - Tiered extraction. Deterministic code parsers handle the common case for free. Content that fails JSON Schema validation escalates to an LLM, and only the hardest cases escalate again to a vision model reading a screenshot. Validation gates every tier, so malformed data never enters the dataset.
Phase 4 - Catalog linking. Extraction transcribes what a listing says about itself. This stage answers the harder question: which product in our own catalog is this. It is the AI mapping system I first built for Reebelo’s catalog in an earlier project, now evolved into the pipeline. Deterministic gates narrow the candidates, an LLM picks only among them, every value is validated against the catalog vocabulary, and a listing that cannot be resolved confidently is refused rather than guessed.
Phase 5 - Training-data flywheel. Every audited LLM extraction and confirmed mapping is banked as a training example, passively accumulating a dataset for fine-tuning a small, cheap model that will take over most extraction work from the LLM tiers.
Phase 6 - Two query lanes. Aggregate questions (averages, spreads, trends) compile to SQL over the extracted data, because vector retrieval structurally cannot aggregate. Semantic questions go to a RAG lane, embeddings over per-listing summaries in a vector index. A tool-using agent routes each question to the right lane and cites its sources. Validated prices keep flowing to the serving systems that power automated repricing, a path that stays untouched while the new layers are proven.

Outcome
The pipeline can turn competitor analysis at Reebelo from periodic guesswork into a live data product, powering an automated repricing strategy backed by real market data. By design, the change gate and the tier cascade keep AI spend at a small fraction of the naive cost.
In production today: catalog discovery, price collection, catalog linking (the AI mapping system) and the serving path behind automated repricing. In progress, and my current focus: the snapshot store, the LLM extraction tiers and the two query lanes. Next on the roadmap: the fine-tuned extraction model, last by necessity, since it trains on the dataset the flywheel is still accumulating.
Change Streams System
The Change Streams System was introduced in my Meteor Impact 2020 talk.
Challenge
As a platform for organizing large-scale online and hybrid events, Pathable (one
of Meteor Cloud’s biggest customers) faced severe performance issues originating
from the way Meteor interacted with the MongoDB oplog. We switched to a
well-known alternative - redis-oplog, but soon realized a major drawback of
this library: Because redis-oplog can’t reliably determine the outcome of a
mutation, it has to perform an extra database fetch after each mutation before
dispatching that change to Redis:
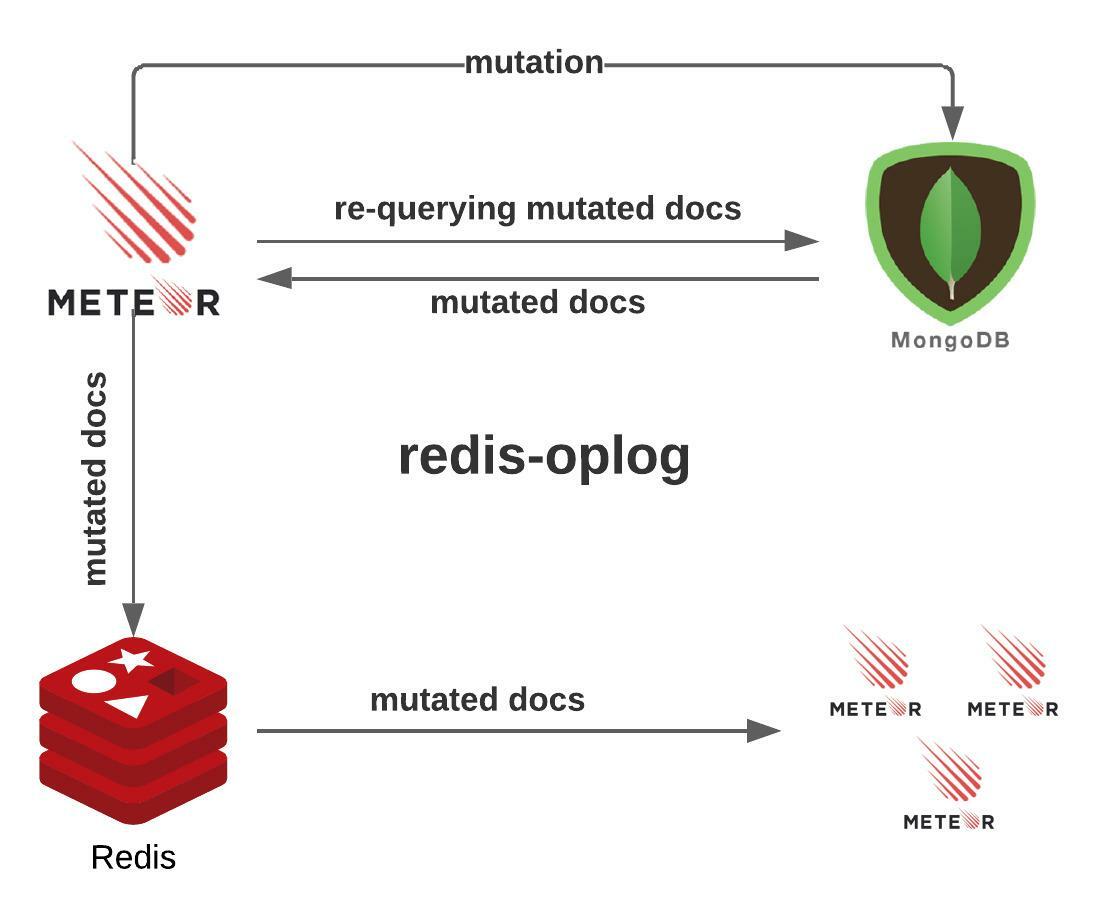
This mechanism consumes database resources unnecessarily and also potentially introduces race conditions.
Solution
I designed an alternative architecture called Change Streams System to
replace redis-oplog. In this system, changes made to the database are captured by a
Node.js server by listening to MongoDB Change Streams which doesn’t introduce
any significant database overhead:
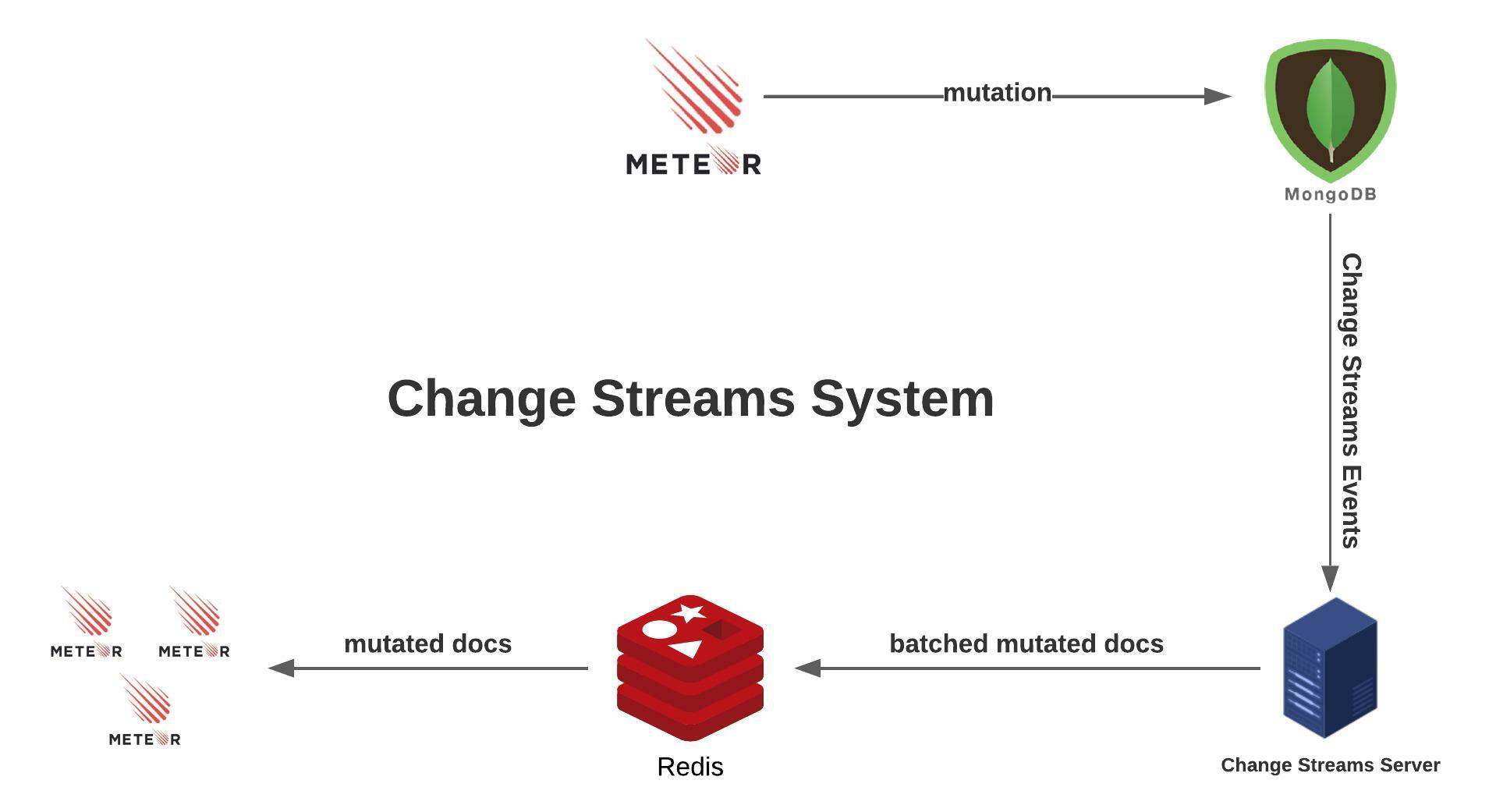
Moreover, before pushing the changes to Redis, the server also processes and merges similar mutations that occur in a short period of time (a common mutation pattern in Pathable), which reduces Redis load significantly.
Outcome
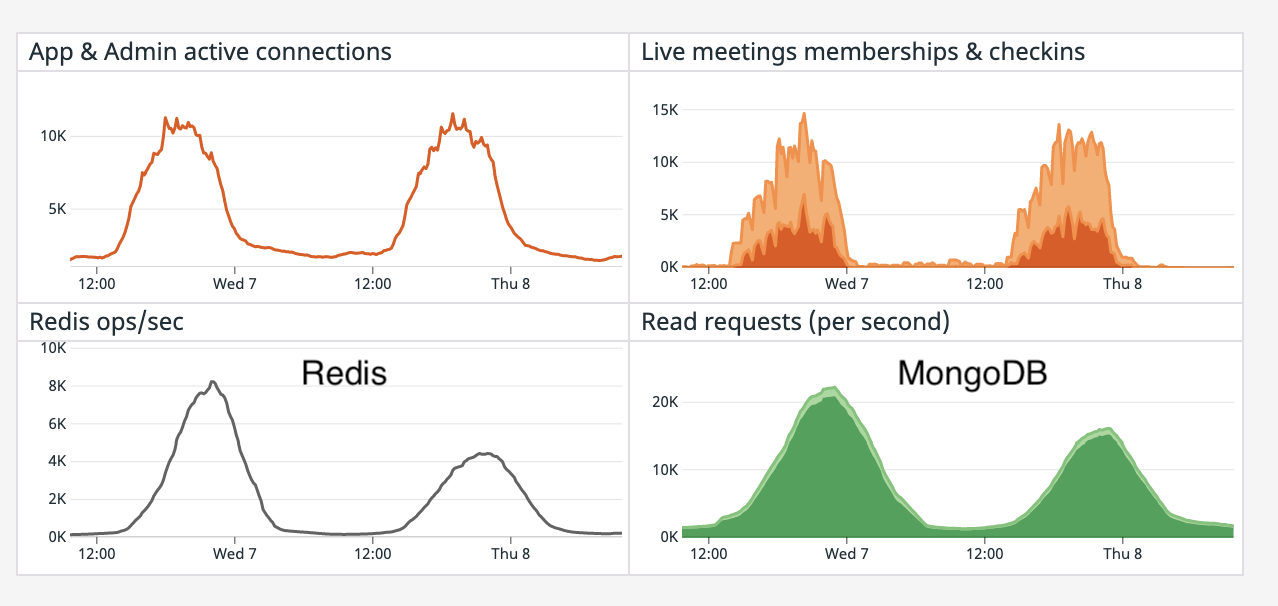
The charts above show metrics of the same Pathable event on two consecutive days with similar level of online user activity, the first day without the Change Streams System and the second day with it enabled.
On average the Change Streams System resulted in a 50% reduction in Redis usage, a 30% reduction in MongoDB usage and helped save hundreds of thousands of dollars in annual infrastructure cost.
Outsmarting The MongoDB Query Planner
Challenge
MaestroQA was struggling with a database query performance issue where queries on a highly active collection took a long time, from seconds to minutes to complete. The collection had close to 100 million documents and more than 20 indexes.
Established practices in MongoDB queries and indexes optimization didn’t help. Caching was not applicable to the use case either.
By performing extensive benchmarking, I realized that during the execution of long-running queries the part taking most of the time is index selection. Apparently the MongoDB Query Planner couldn’t efficiently handle such a complex indexes structure. That said we couldn’t reduce the number of indexes because the range of query patterns on the collection was so diverse that removing any existing index would cause a large number of COLLSCANs.
Solution
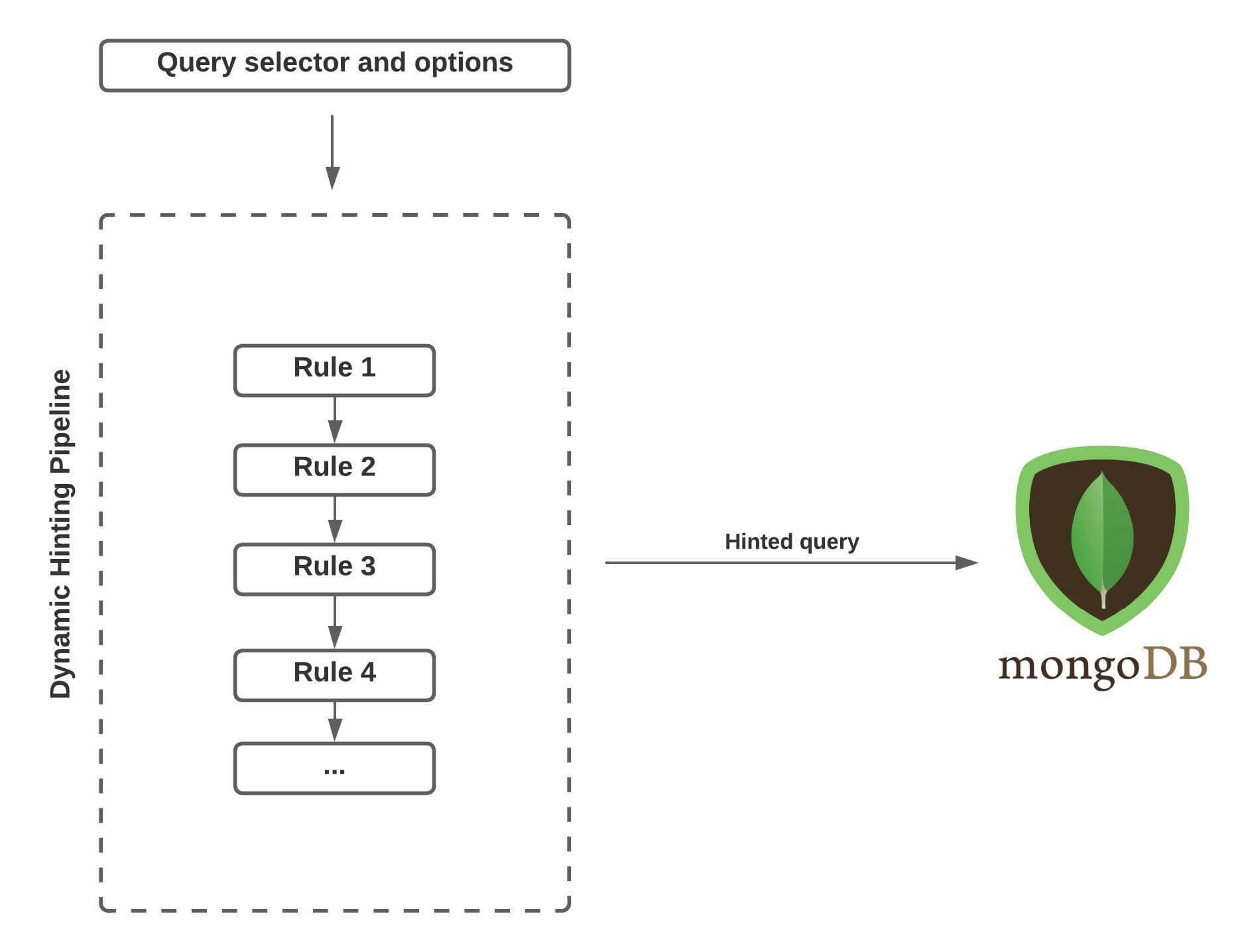
I experimented with an idea called Dynamic Hinting where we attempted to do the
job of the MongoDB Query Planner: Selecting an appropriate index at the
application level and adding a hint to the query before sending it to MongoDB,
effectively bypassing the Query Planner.
In order to pick indexes for our sophisticated queries, we implemented a Lambda that periodically pulls slow query logs from Atlas and pushes them to Elastic for analysis purposes.
By thoroughly analyzing the patterns of slow queries, their selectors, options, and the duration they took, we were able to come up with a set of “dynamic hinting rules” and use them to build a pipeline that can confidently suggest an ideal index for various query patterns (or just fall back to the Query Planner when there aren’t enough data and confidence to make an index decision).
Outcome
The experiment resulted in encouraging performance gain, where the number of
queries taking more than 100ms was reduced by 58%
and the number of queries taking more than 1 second was reduced by 61%.
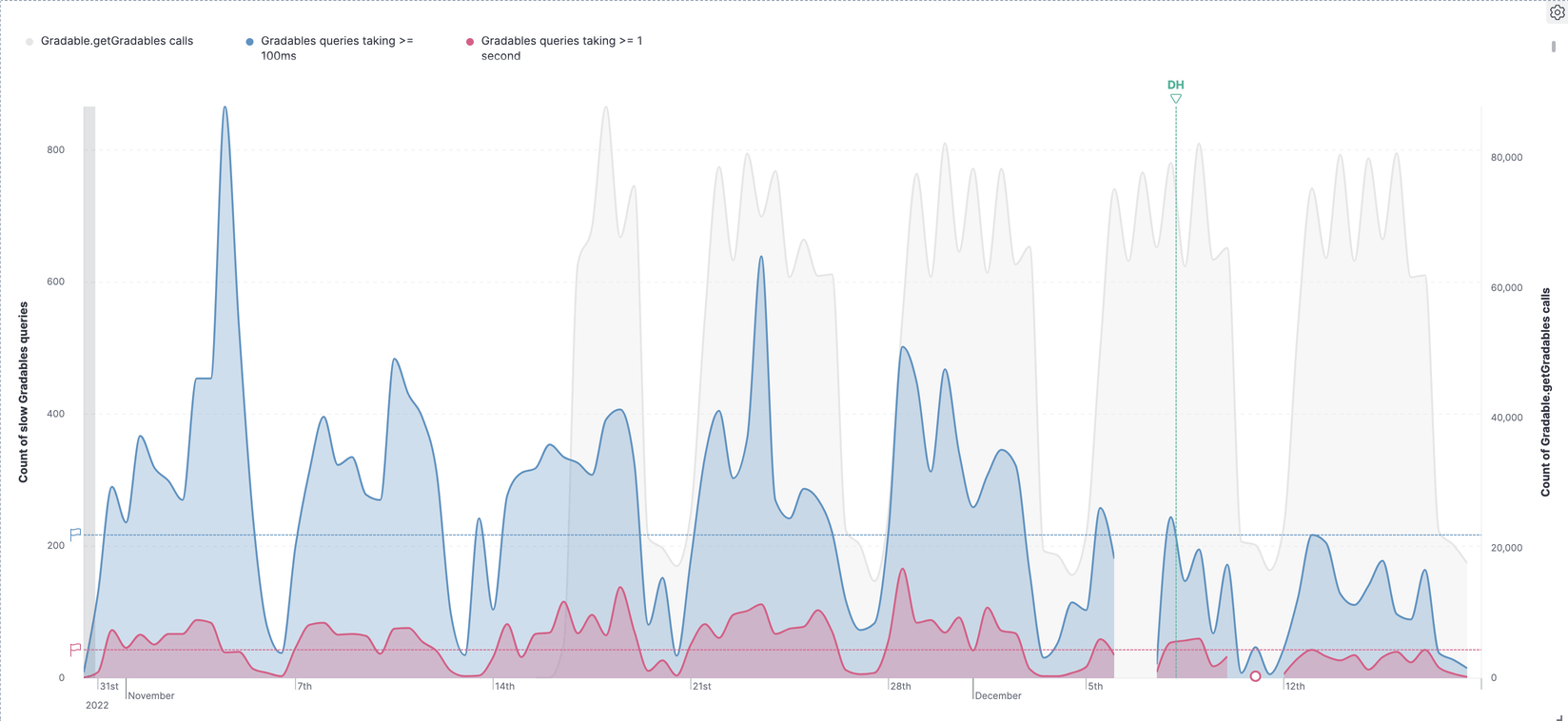
(The vertical green "DH" line indicates the time Dynamic Hinting was released)
Dynamic Hinting still has a lot of potential, and we expect to increase both the coverage and the aggressiveness of hinting rules as we get more data and insights after the initial release.
Serverless Pub/Sub for Meteor
Challenge
Pub/Sub has always been both the strength and weakness of Meteor. While the feature allows developers to build reactive apps effortlessly, its performance suffers when implemented at scale.
Meteor Pub/Sub doesn’t scale well because there’s too much overhead to maintain a publication observer and that overhead increases exponentially with the number of clients, especially when subscribe patterns are diverse and observers can’t be reused.
Solution
To address that scaling weakness of Meteor, I built an experimental architecture called serverless-oplog, built on top of technologies such as Cloudflare Workers, Cloudflare Durable Objects and MongoDB Change Streams.
serverless-oplog handles Meteor Pub/Sub workload serverless-ly
by assigning a dedicated Durable Object to each DDP client and having all of the client’s
Pub/Sub activities processed by the Durable Object. As new clients connect, new Durable Objects
will be spun up, giving us infinite scalability.
On the Meteor side, the server just needs to serve the initial data fetched from publish cursors (which will also be offloaded to Cloudflare in a future version of serverless-oplog). There is no observer created at all, which means we have basically migrated the entire Pub/Sub overhead away from the Meteor server!
The architecture is illustrated in the following diagrams:
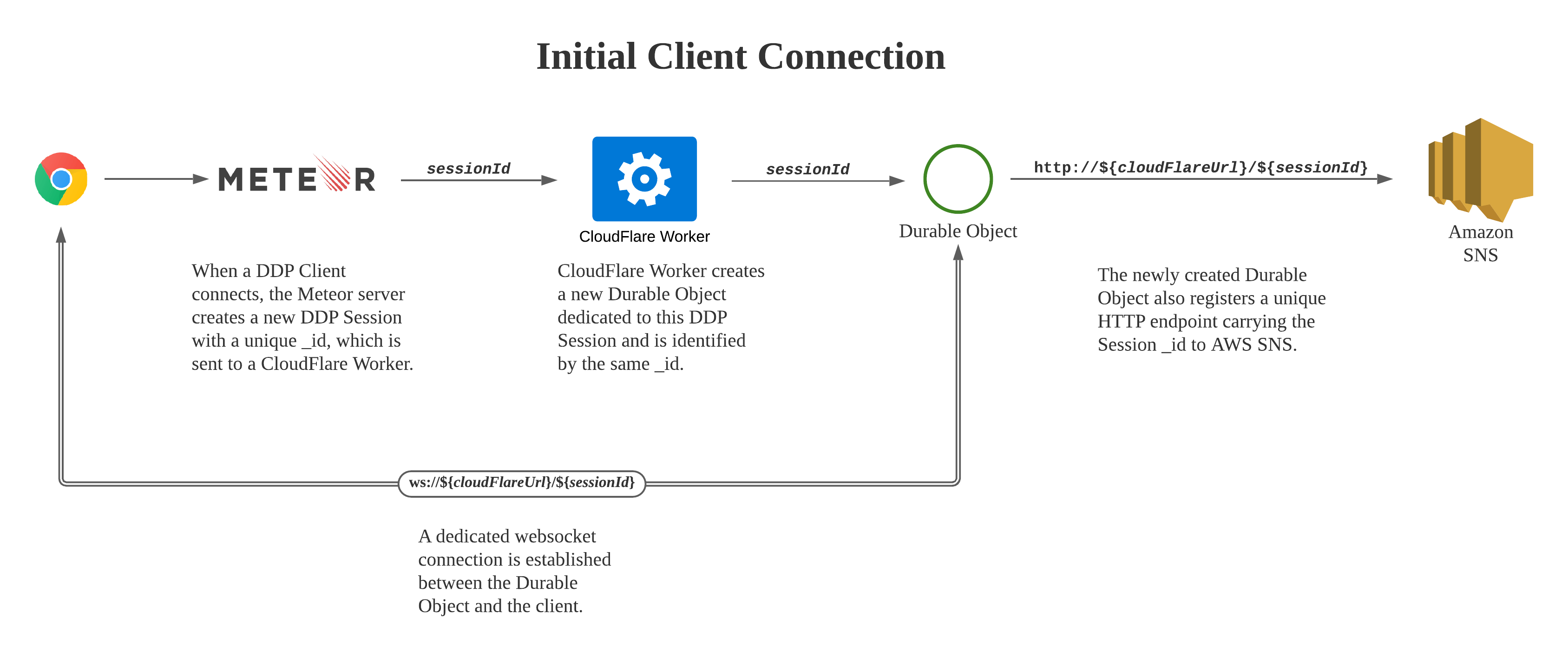

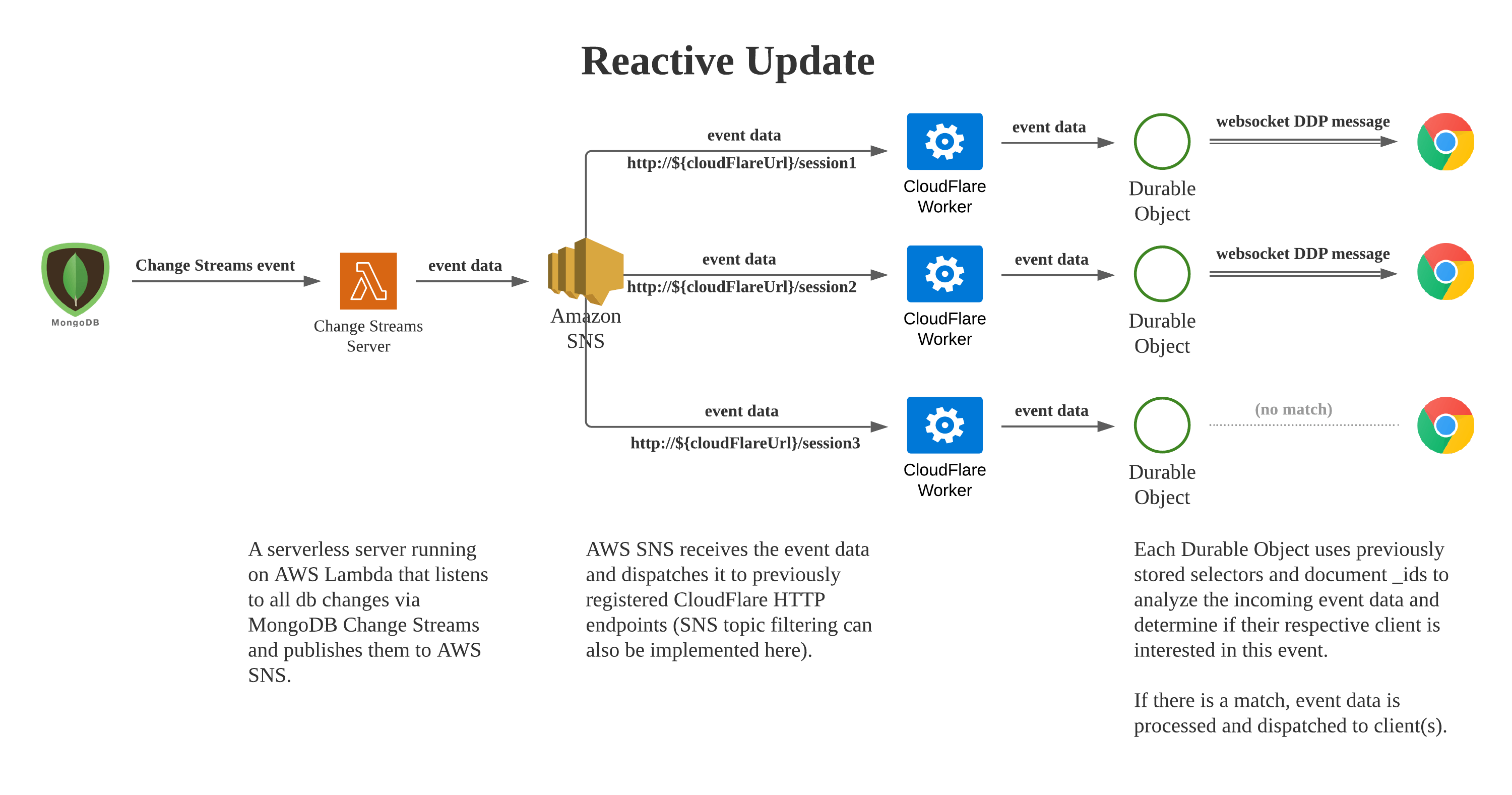
Outcome
The architecture write-up and code live on GitHub.
Faster Than Light Chat System (FTL Chat)
Challenge
Despite having an indeed funny name, FTL Chat was an interesting project where we were facing a time-constrained challenge: A very large-scale event (up to 60k participants) was contracted and one of their main priorities was online chat. Our chat system at the time was built on top of Meteor Pub/Sub, and by benchmarking we realized that the system wouldn’t be able to handle more than 1k users chatting at the same time across different chat rooms.
Solution
Since the event contract came at a short notice, we had to think of solutions to offload chat overhead away from our Meteor servers entirely, since it would take a long time to optimize Meteor for this kind of load.
I proposed an idea about using AWS AppSync as the new backend for chat, which eventually became the architecture for the FTL Chat project:
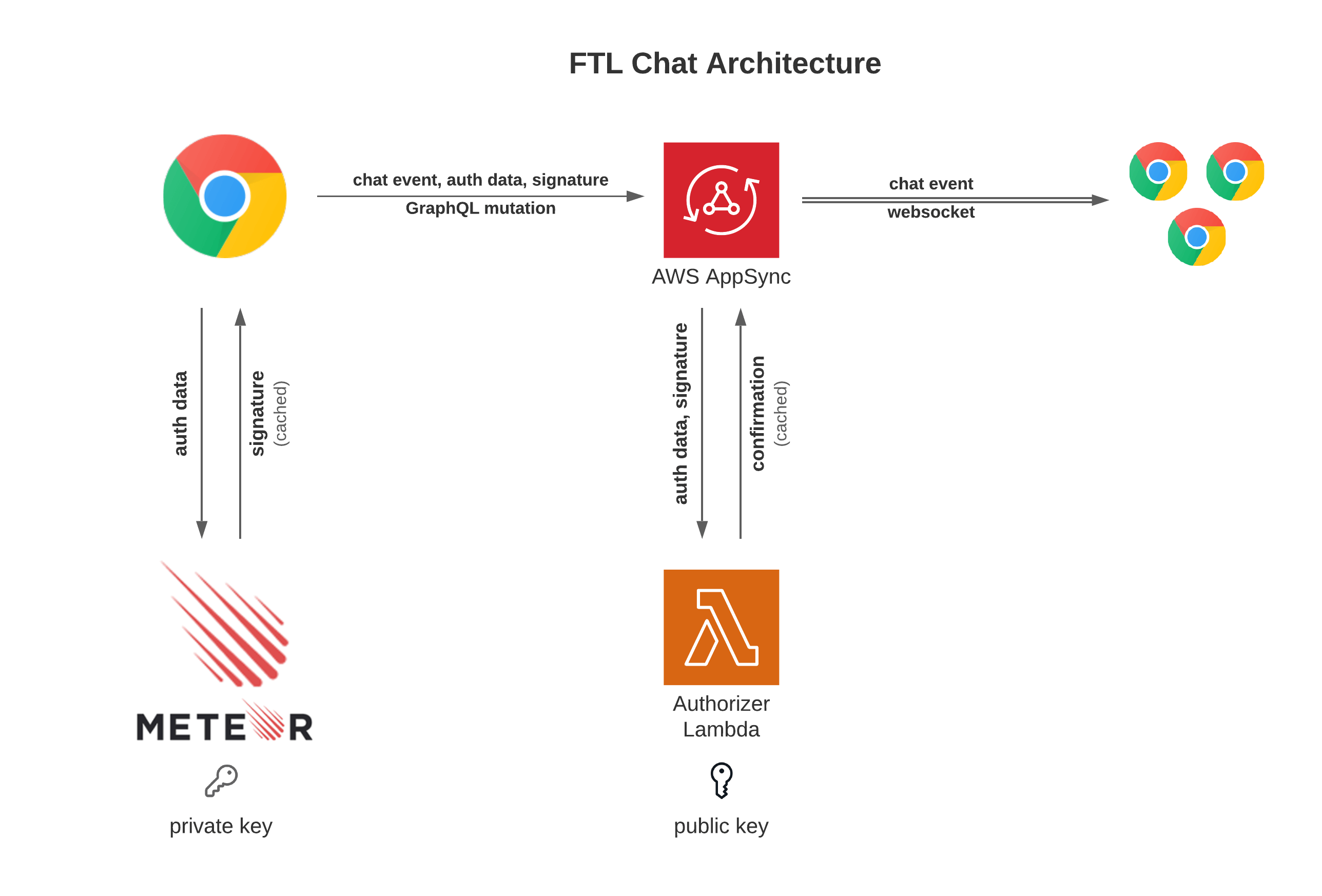
A novel feature of FTL Chat is its ability to integrate seamlessly with the Meteor accounts system by using public-key cryptography and AWS Lambda, with an authentication caching strategy that introduces minimal performance impact to the Meteor servers.
Outcome
FTL Chat effortlessly served 10k simultaneous chatters in the event and eventually replaced the old chat system in production.
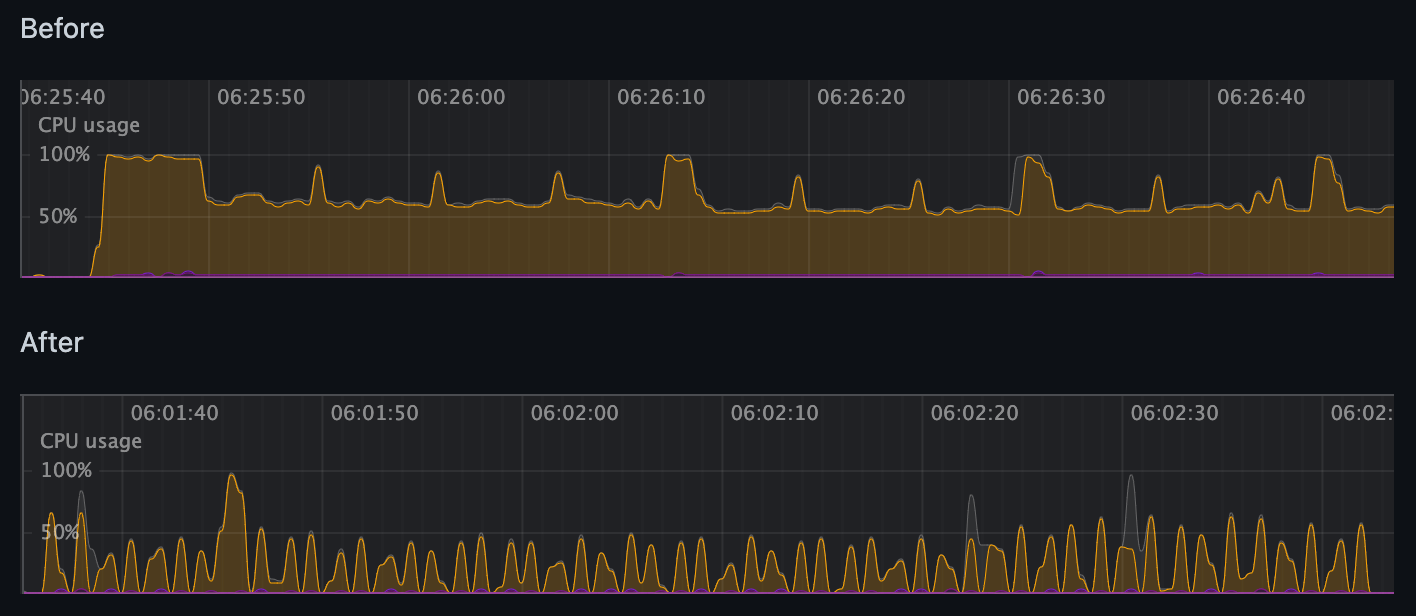
Throttled Reactive Rendering
Challenge
During a large online event we encountered a client-side performance problem where browser CPU was constantly pegged, severely affecting UX. It turned out the reactive computations underlying our UI were being rerun too fast because of very high volume of incoming realtime data.
Solution
Instead of limiting or even turning off reactivity (which was undesirable for the event), I developed a custom re-rendering mechanism for React over reactive data. A naive throttle at the application level didn’t work, so I went one layer down into the reactivity engine itself and changed how subsequent recomputations were scheduled, effectively capping the re-render rate while keeping the UI fully reactive.
Outcome
Client-side CPU usage improved significantly:
Other notable open-sourced projects
-
pub-sub-lite: Simulating Pub/Sub with Meteor methods.
-
ddp-health-check: DDP performance monitoring for Meteor.
-
meteor-typescript-import-transform: Fixing deprecated legacy TypeScript patterns that no longer work with the official Meteor
typescriptpackage.